A Psychogeography of Latent Space
Part of PRiSM Future Music #2
15 June 2020
Introduction
 Dr. Sam Salem is PRiSM Lecturer in Composition. This text is an artistic reflection on composition in the age of Machine Learning, written to accompany the public launch of PRiSM SampleRNN, a collaboration between Dr. Christopher Melen and Dr. Sam Salem.
Dr. Sam Salem is PRiSM Lecturer in Composition. This text is an artistic reflection on composition in the age of Machine Learning, written to accompany the public launch of PRiSM SampleRNN, a collaboration between Dr. Christopher Melen and Dr. Sam Salem.
Today also marks the public launch of our first PRiSM SampleRNN model, the Choral Model.
The Choral Model is a significant development for PRiSM, combining our access to the RNCM’s unique and world-class archive of recorded media with the PRiSM Deep Learning workstation and our research into Neural Synthesis.
We look forward to updating and further developing PRiSM SampleRNN over the coming months, and we intend to periodically release new models based on different subsets of the RNCM archives.
PRiSM SampleRNN Github
PRiSM Choral Model Dropbox
PRiSM SampleRNN Google Colab Notebook
A Psychogeography of Latent Space
By Dr Sam Salem
Lost in Space / An Introduction
When I think about music, I find myself thinking about space. About traversal through and between different spaces. As I compose, I ask myself: where does this section begin? Is its journey direct or circuitous? Does it take a well worn road or an unknown trail? Is its destination the one that I had imagined?
I imagine motion and trajectories, points on maps.
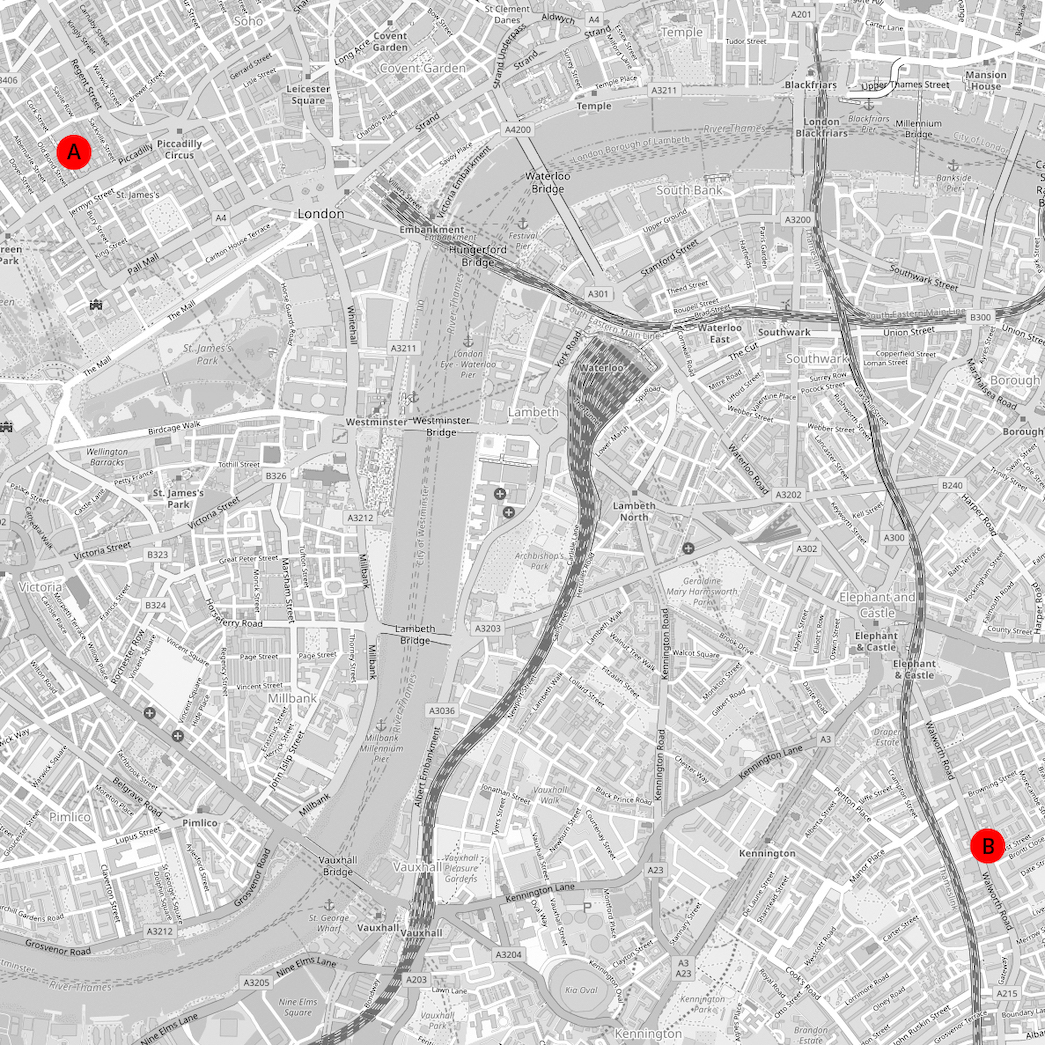
Let’s imagine one together. It is a very simple map, containing only two points, A and B.
Point A marks the location of the Royal Academy of Arts in Burlington House, Mayfair, London.
Point B hovers above 56 Walworth Road, just south of the Elephant and Castle Underground station.
If we trace a line from A to B, what might it describe? Perhaps the simple fact of physical distance, 2.5 miles by road. Or perhaps the line tells us something about wealth, inequality and class, connecting, as it does, one of the most luxurious parts of London with a traditionally working class district.
In my telling, this 2.5 mile long line describes the arc of the life of Austin Osman Spare, artist, occultist and cult figure. In 1904, aged 17, Spare became the youngest artist to exhibit work at Point A. In 1941 his studio – and home – at Point B was destroyed in the Blitz, the explosion damaging his hands and memory.
A to B, 1904 to 1941, 2.5 miles and 37 years: the promise of youth, the reality of that promise unfulfilled, the punctuation of tragedy. If we met today and walked from A to B, what other points would we discover, and what lines would they suggest? What other threads would catch our eyes and ears, and what kind of narrative would we weave?
The activity that I am describing, this act of “ambulatory divination”, is the practice of psychogeography, a particular (and perhaps unusual) approach to the poetics of space, place, myth and history. In 2016 I walked the route between A and B, as well as many other routes in and around central London, in order to collect materials for Untitled Valley of Fear, a work inspired by Austin Osman Spare.
Organised Sound
A theme, in this case the life of Spare, can not only delineate the conceptual territory of a work but also suggest a set of physical locations from which the raw materials that are used in the creation of the work will be gathered. The materials can include field-recorded sounds, video recordings as well as the occasional physical object.
The theme can also suggest a specific means of creation, and it is one such process, which we could loosely describe as the Manufacture of Uncanniness, that I wish to focus upon now.
Space, place, myth and history – the way in which I approach composition is to recognise the myriad conceptual spaces that exist within a work and then use this understanding to navigate the total possibility space of the work.
To clarify this statement, let’s imagine that we have a small set of materials: Sound A, Sound B & Sound C.
Despite being a very limited collection, these materials can still be grouped and organised in many different ways. Each grouping creates a “space” that tells us something about both the nature of each object and how each object relates to every other.
We could focus our listening attention on the extrinsic, or explicitly extramusical, qualities of our collection and make a number of quick distinctions. For example, it is clear that A and B are field-recordings while C is a synthesised tone. Similarly, if we were to categorise these sound objects by source location, we would find that A and B originated in St James’s Church, Piccadilly (where William Blake was baptised in 1757) while C originated in my studio in North London.
If we were to switch our focus to the intrinsic, internal characteristics of these sounds, and practice Reduced Listening, we could again make several easy distinctions. If we were to classify these sounds based upon spectral content, we could state that A is entirely noise-based, B is noise-based but with a constant tone at around 40 Hz, and C is entirely harmonic with a fundamental frequency of 258 Hz. Similarly, we could state that A and C are more gestural in nature, while B is more textural, and so on.
In this way, no matter the sonic contents of our collection, we can construct different “spaces” of organisation using our chosen parameters or features, prioritising those which are more important or valuable at any given moment in the trajectory of the composition.
To follow this line of thought to its logical conclusion, we could describe the musical work that emerges from these objects as only a single traversal through a kind of compositional “hyperspace” that consists of many layers of spaces, each describing a parameter, or feature, of my collection of objects. My knowledge and experience, my musical taste, ultimately determine the shape and extent of this hyperspace, as I am either consciously or subconsciously determining important features and hierarchies.
Computer-assisted compositional techniques are one way to break away from the cul-de-sac of personal taste. However, if we create our own tools, even if they are based upon generative or aleatoric ideas, we run the risk of simply reinforcing our biases in another area of the compositional workflow. And if we rely on the tools of others, we become susceptible to falling into cliché.
Collaborative partnerships are also a very powerful way to extend the possibility space of a work. But what if we collaborate with something that isn’t another person? And could explore a different hyperspace, based not only upon a different set of parameters and criteria, but a different type of knowledge altogether?
Latent Space
In the simplest terms, Machine Learning allows us to create models that are then used to generate new outputs. Latent Space is the internal, hidden world of the model, shaped via the process of training on a given data set, or corpus.
The model predicts a possible future, based on what the algorithm has taught itself through the training process. I can’t stress how crucial this point is. Without any context, or conditioning, the algorithm teaches itself. The Latent Space of the model, and the manner in which the algorithm discriminates data and infers features, is a black box to the end user. For those new to Machine Learning, I recommend that you read Dr Christopher Melen’s excellent A Short History of Neural Synthesis.
From my perspective as an artist who has worked with Machine Learning, a few aspects of this paradigm seem particularly exciting. The parallel between the Latent Space of the machine and my “compositional hyperspace” is that, much like the algorithm, my role as a composer, or creative decision maker, is quite similar to that of the network. I reduce the complexity of a heterogenous data set to several key data points, which I then organise using salient parameters of my own choosing. My navigation of this process occurs both consciously and subconsciously.
One significant difference is that for me, contextual information is absolutely vital: for a psychogeographer, a walk is never just a walk. In contrast, the algorithm requires no context for the data it is learning from. It will infer features for itself and construct its own representation of the information contained within the corpus.
I’ve spent many months working with these models, learning to co-exist in my studio with a very powerful PC that purrs in the corner of the room, raising the ambient temperature in a way which gives me a physical sense of its labours. Having spent a considerable amount of time listening to its output, I still can not tell you what exactly the machine learns, but I can tell you that it does not listen in the same way that we listen.
Midlands (2019)
In 2017, when I began composing my large-scale chamber ensemble work Midlands, one of the many threads that I was excited to explore was the history of Derby. Due to Derbyshire’s central role in the Industrial Revolution, I walked the 100 or so kilometres of the River Derwent, the power source of many early mills. The materials I recorded formed the basis of the fourth movement of the work, “How To Build A Machine”.

Masson Mills Weaving Shed | Photo Sam Salem

The source of the River Derwent | Photo Sam Salem
I made the decision to use Neural Synthesis in Midlands for two reasons.
Firstly, I believe that Machine Learning and Artificial Intelligence have the potential to spark a new Industrial Revolution. Of course, how you feel about this may be influenced by whether you own the loom, so to speak: whether you are the person whose livelihood is being disrupted rather than the disruptor who stands to benefit. However, it is safe to say that we do not yet fully understand the effect that these technologies will have on the future of work, let alone creativity. I therefore felt it was apt to use Neural Synthesis with field-recordings made at locations associated with the first Industrial Revolution.
Secondly, in my opinion Neural Synthesis represents the first genuinely new category of sound synthesis of this century. If we look at a very brief, general (and non-definitive) history of sound synthesis, we can trace a path from Additive and Subtractive Synthesis (1950s), via Frequency Modulation Synthesis (1960s), Granular Synthesis (1960s), Wavetable Synthesis (1970s), Physical Modelling Synthesis and FFT / iFFT Analysis and Resynthesis (1980s/1990s).
There have been myriad exciting developments in music technology over the last 30 years, with the success of Eurorack Format in recent years in particular leading to a renaissance of signal processors, synthesiser voices and modulation sources. The average studio is several orders of magnitude more powerful than its 1990 equivalent. But, despite the increase of processing power, the huge increase in the complexity of sound synthesis and processing, and the democratisation of access to music technology, the fundamental building blocks of electronic sound have remained relatively fixed for a remarkably long time.
In order to create material using Neural Synthesis for Midlands, I trained the Wavenet algorithm on my database of 3,000 field recordings. The following sound file is one of the synthesised outputs.
The first part of the recording that we hear is the seed, which in this case is the trickle of the source of the River Derwent, north of Howden Reservoir in the Peak District National Park. What follows on from this is the Wavenet algorithm trying to predict what should happen next.
We can hear that our generated sound has an organic and environmental quality, but that it is nonetheless a little bit… off. It is not quite noise and yet not correct enough to be a completely believable field-recording of a natural environment. It is something else, something Uncanny.
The following excerpt of Midlands contains many different layers of sound material generated using Wavenet:
SampleRNN
Working with the Wavenet algorithm during the creation of Midlands was rewarding but also extremely challenging. The several dozen files that I was able to generate during the compositional process were ultimately sufficient, but the speed of the workflow made it largely impossible to explore the full possibility space of the technique. I literally ran out of time.
SampleRNN, a Neural Synthesis algorithm made famous by Dadabots, was reputed to generate sound more quickly than Wavenet. However, SampleRNN presented a different set of challenges: the available code was seemingly broken.
After extensive discussion with Dr. Christopher Melen, PRiSM Research Software Engineer, we decided that SampleRNN represented a fantastic opportunity to both explore Neural Synthesis and contribute to the ML community. Chris undertook a complete reimplementation of the SampleRNN code, fixing broken dependencies and upgrading the code to work with the latest versions of Python and Tensorflow. I tested, prodded, and asked a lot of questions.
My initial tests of the resulting PRiSM SampleRNN code focussed upon training models on a corpus of my own music, in this case the entirety of Midlands. The results were immediately promising:
In these examples, we can hear how singer Ute Wassermann’s voice emerges from noise and dissolves into a sustained pitch. While these timbres are contained separately within the corpus, the interpolation between them, the timbral trajectory of these sound objects, is completely original. I found the examples fascinating, but they stemmed from a piece which was already completed. I therefore began to consider how best to use Neural Synthesis as a key process in an entirely new work.
A Map of Weston Olencki
In 2018, I visited Spartenburg, South Carolina, the hometown of trombonist Weston Olencki. Weston had commissioned me to write a new work for solo trombone, and the purpose of the visit was to gather materials and ideas.

Images of South Carolina | Photos Sam Salem
Alongside the map of Weston’s home town and early life, I wished to construct another kind of map, of Weston’s relationship to his instrument. In order to do this, PRiSM invited Weston to the RNCM in December 2019 in order for me to capture a large range of his performance techniques and idiosyncrasies. The resulting recording sessions have so far yielded over 2000 individual sound recordings. So while the corpus is not quite every sound that Weston can make, it is certainly close!

Recording with Weston Olencki at RNCM, December 2019 | Photo Sam Salem
I am very excited to share for the first time some early results of training the PRiSM SampleRNN code on the corpus of Weston’s extended techniques:
These materials mesmerise and provoke me: I am not exactly sure what to do with them. This is both an extremely rare and amazing problem to have, which I look forward to solving.
What compositional strategies could be employed? One strategy could be to transcribe these sounds for Weston to perform, but are they even playable on a real trombone? After all, the algorithm doesn’t know (and hasn’t learned) anything about human physiology. Another strategy could be to think of the final piece as a kind of dialogue, or even argument, between the real Weston and his Uncanny twin, his doppelgänger.
A Dérive in the Uncanny Valley
Freud described the Uncanny as a “province… that undoubtedly belongs to all that is terrible – to all that arouses dread and creeping horror”, arising from a situation in which the familiar becomes unfamiliar. Building on Freud’s definition, roboticist Masahiro Mori coined the term the Uncanny Valley in 1970, describing how as robotics approach human form they provoke an “eerie sensation”, a lack of affinity, or in Freud’s conception of the Uncanny, a sense of “creeping horror”. The famous graph Mori used to describe this phenomenon can be found in his original essay “The Uncanny Valley” (Figure 1 below).
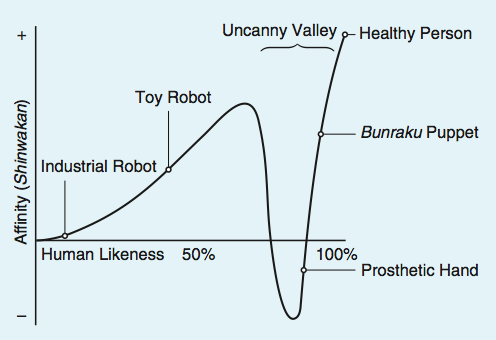
Figure 1: The Uncanny Valley by Masahiro Mori
Machine Learning has the capacity to Manufacture Uncanniness, to create materials that are both strange and familiar, and difficult for the listener (and composer) to parse. But, for me, this is not a cause of discomfort or displeasure, rather, it is the opportunity for a walk in a strange place, where objects do not fully make sense and are also not fully nonsensical.
This liminal space feels hypnagogic: I have the strong sense that there is a dream logic at work that is just out of reach. The resulting sound objects are reminiscent of the automatic drawings of Austin Osman Spare, as well as the work of Surrealist artists such as Breton, Soupault and Dali.
When this technology matures, when its outputs are indistinguishable from human creativity, when we can’t tell whether the piece we are listening to is generated by an app or an artist, I suspect that this technology will cease to be of any interest to me.
It is this moment that feels so exciting, precisely because the outputs are delirious, slightly broken, angular, inscrutable and ambiguous, with odd swoops and unexpected points of inflection.
In the spirit of the Surrealists, I’d like to end this text by leaving you with a model trained specifically for this purpose, inspired by Dali’s Lobster Telephone:

Salvador Dali’s Lobster Telephone
Lobster Telephone
My recipe for this model involves the following sonic ingredients.
Combine:
- 2 Shiny lobsters
- 1 Mantis shrimp
- 1 Snapping shrimp
- 1 Sea Urchin
- 1 Northern Seahorse
- 1 Atlantic Croaker
- 1 Rotary Telephone (UK)
- 1 Series of mobile phone vibrations
- 1 ASMR recording of a lobster being eaten (insert unhappy / queasy emoji here)
- 1 Facebook video of Lobster Sound, a dub sound system based in Cologne
Simmer for 24 hours. Retrieve output, and serve immediately.
![]()
