Oracle: The Dreaming Species
17 March 2022
Introduction

Melanie Wilson, photo by Helen Murray
The multi-disciplinary performance maker Melanie Wilson started her collaboration with RNCM PRiSM and the producing company Fuel in 2021, as part of Sound and Music’s New Voices Composer programme.
This project, Oracle: The Dreaming Species, has manifested as a choral project that uses sound and music to explore the human connection with non-human species.
In this PRiSM blog, Melanie shares with us how she has been using PRiSM SampleRNN to communicate with an ensemble of human and animal voices.
She reflects on her recent experience of working with eight singers, which culminated in an informal public sharing event at the International Anthony Burgess Foundation in Manchester, February 2022.
Oracle: The Dreaming Species
Creating Hybrid Vocalities as an Act of Inter-species Solidarity
By Melanie Wilson
Through Sound and Music’s New Voices composer programme and the support of Fuel, I began a collaborative machine learning partnership with RNCM PRiSM in 2021, with additional mentorship from Dr Sam Salem (PRiSM Lecturer in Composition).
The impetus for this project was a response to the crisis of biodiversity. Since the industrial revolution, the UK has lost almost half of its biodiversity, a winnowing birthed in Manchester, the place I make home. This is not to hold Manchester responsible, more a way to root specificity of thinking into the place I stand, and into the partnership with PRiSM: a way to anchor this work within a storm too huge and slowly moving to really fully comprehend.
I have set out to make a choral project that uses sound and music to explore the human connection with non-human species. I started with the question: can a language for sound be created that allows the listener to perceive interdependence with other species, whether poetically or actually?
I have done this because I personally feel a deep enchantment with the intelligences we share our world with. I want to draw closer, to treasure our fraying bond, to feel less alone and insane.
Non-human intelligence salves us, but it’s more than that: it’s an essential presence for the way we think and without it we are isolated in a looping cerebral cage.
I wanted to co-create the beginnings of this project with a neural network, to explore a vocal aesthetic that stages a meeting place in sound between humans and animals: a speculative voicing, within which to play. I wanted to work with a mechanism that listened for different relational aspects in those voices, that whilst not exactly circumventing my anthropocentric biases, perhaps re-framed them in a way that allowed new insights or alternative paths towards encounter.
Animals
I began by collecting a cohort of vocalising animals, both native and global. Immediately there was the question of privileging animals like wolves, indri or song thrush, that occupy ranges and sound expressions more easily accessible to human voice: an anthropocentric favouring.
This remains a live question. I built on these voices with other types of sonifying animals like wart biter crickets, who stridulate to create sound, or bats who echolocate. Also included were common loon, great bittern, corncrake, humpback whale, natterjack toad, red squirrel, gibbons, otter, turtledove, arctic fox, elk, puffin, orangutan, orca, nightjar, honeybee, hedgehog and lynx.
I spent a lot of time listening to these animals, trying to extrapolate motifs and phrases that I could notate into music, or translate into vocal tactics to share with a singer. I thought about the erasure of animal microtones when translated into an equal tempered scale, and that scale being an example of the force of western human organisation. I also thought about the scale as a working location to situate the human ‘story’ in the project specific to my cultural context, and a place to travel out from towards the pitch sphere of animals and their story.
First Training
The first training phase with PRiSM SampleRNN was based on equal proportions of animal and human voice examples. The animal audio was sourced from a wide range of pre-existing location recordings, from a range of different sources, including a collection made by composer and field recordist Sarah Keirle.
I composed a set of studies in response to a selection of animals, for one voice. These studies responded to whales, wolves, crickets and bats, and took motifs and rhythms within the voices as their basis.
In June 2020, I worked with soprano Peyee Chen to record these studies. The dataset was compiled and sent to Dr Christopher Melen (PRiSM Research Software Engineer) for training.
PRiSM SampleRNN’s responses to this first training session were fascinating. They sounded febrile and kaleidoscopic, and deeply fidgety: a kind of high energy collision of species, heard through radio static. Maybe shortwave reports from the front lines of a war or a ball on a far distant planet?
There was definitely the beginnings of a type of voice hybridity, heard in glimpses, most often at the beginning or ending of a sound. Something like the in breath of a human followed by the decay tail of an orca or indri.
The density and pace of the material felt really challenging to penetrate, but the glimpses of something novel and uncanny spurred me to try to get closer to the possibility of a more unified voice through a second training session.
Second Training
I began by long listening to PRiSM SampleRNN’s responses, a process I have to say I could sustain for about an hour at a time before a sort of focus fatigue set in.
Informed by conversation and process sketching with Sam, I gained some purchase on my new collaborators output by making edits of all the instances I thought I could hear of it creating hybridity.
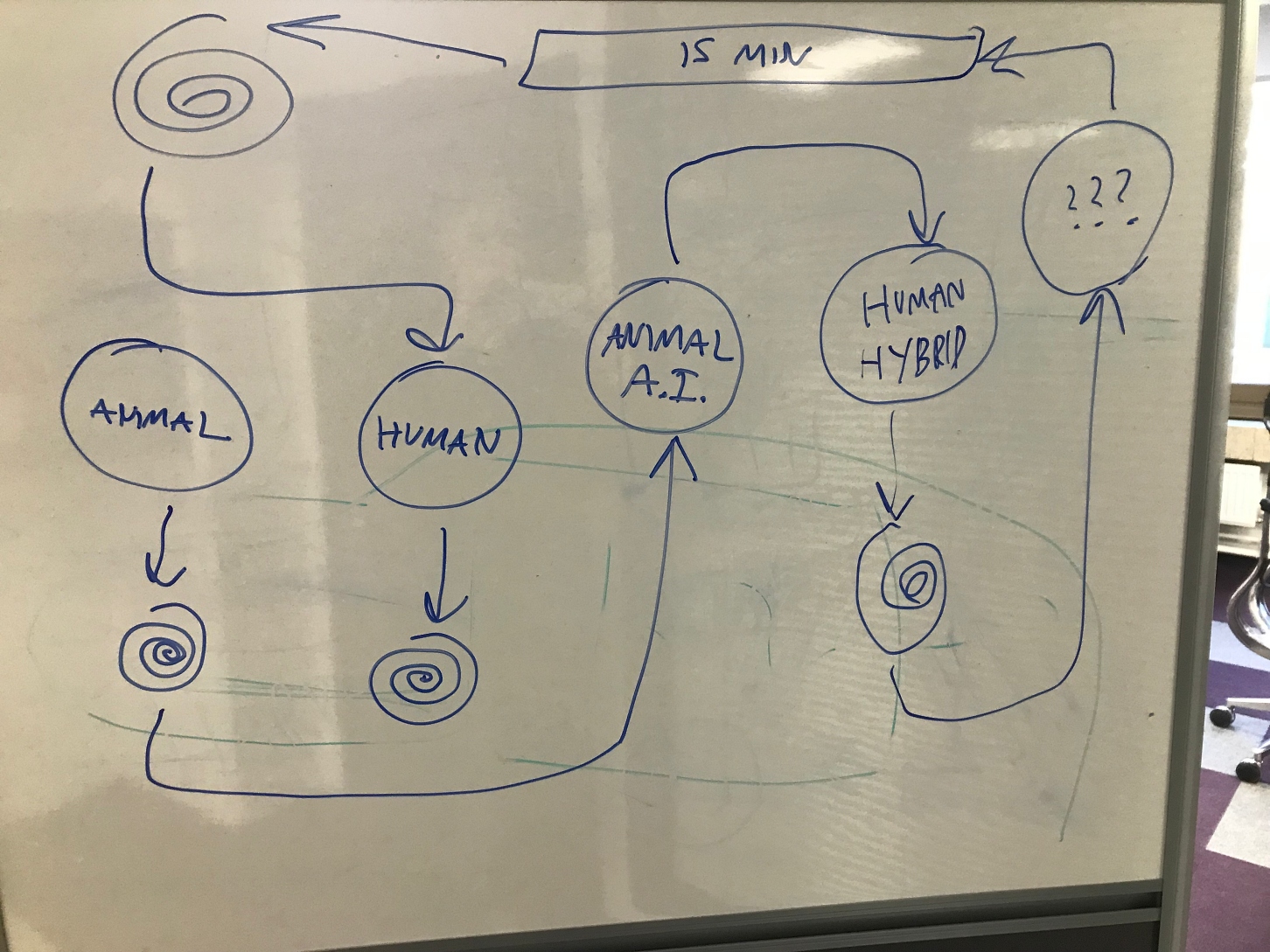
A sketch for training PRiSM SampleRNN, by Dr Sam Salem, written on the PRiSM whiteboard.
In a second recording session with singers Peyee Chen and Héloïse Werner, we recorded the human response to PRiSM SampleRNN’s material. We did this in two iterations. Firstly by singing back as accurately as possible the excerpt heard, secondly by developing the idea heard into a new proposal, through improvisation.
We also applied this same iterative process to singing the replication of and answer to the same set of animal voices. This time though, I edited the collection to focus on recordings of animals that minimised background noise, so that the information PRiSM SampleRNN was learning was as cleanly vocal as possible.
I became aware here of how this process separated the voice of the animal from its context of rainforest or shore. I thought about how this separation perhaps perpetrated the very dislocation that the project seeks to question, and began to think about the voice as a composite force: a mechanical process, an expression of identity and a manifestation of the systems of life.
In December 2021, PRiSM SampleRNN set about learning this new set of training material and the results were markedly more vocal and more hybridised in expression. To my ear, what emerged now was something that sounded more like animals attempting human speech, almost like an eerie, anxious inter-species puppeteering.
In listening there is the sense that any moment some revelatory breakthrough will be heard, some establishment of balance and conviction, but this release is always just out of reach, just beyond. PRiSM SampleRNN’s voice wandered and ranged, remaining unsettled, and for me, unresolved.
Now my task was to question my terms of engagement with the software, to begin to understand the actual rather than possible parameters it had opened up for me, as I took its material into preparation of music for an ensemble to sing.
Humans
As I worked my way towards a week of R&D testing in February 2022 with eight singers, a few tactics have emerged.
One section of the score employs in-ear listening and replication of PRiSM SampleRNN, which is collaged and built upon across the eight voices.
Another section employs text instructions across a timeline to create a fictionalised portrait of how a recurrent neural network learns.
Another section employs the heavily processed, AI-generated voice together with a whale as two soloists, moving in relation to a live choral accompaniment underneath.

Testing music with Héloïse Werner, Kate Huggett, Adey Grummet, Rosie Middleton, Melanie Pappenheim, Benoît André, Robin Morton, Edmund Phillips and Michael Betteridge. Action shot from the R&D showcase in Manchester, February 2022.
The ongoing identity of PRiSM SampleRNN as a legible presence in the music is a process I’m still reflecting on.
It is true that perhaps no machine is better suited to creating strange and confronting renderings of other vocalising species than the human voice itself, so what have I gained by asking a neural net to undertake this very complicated and nuanced task?
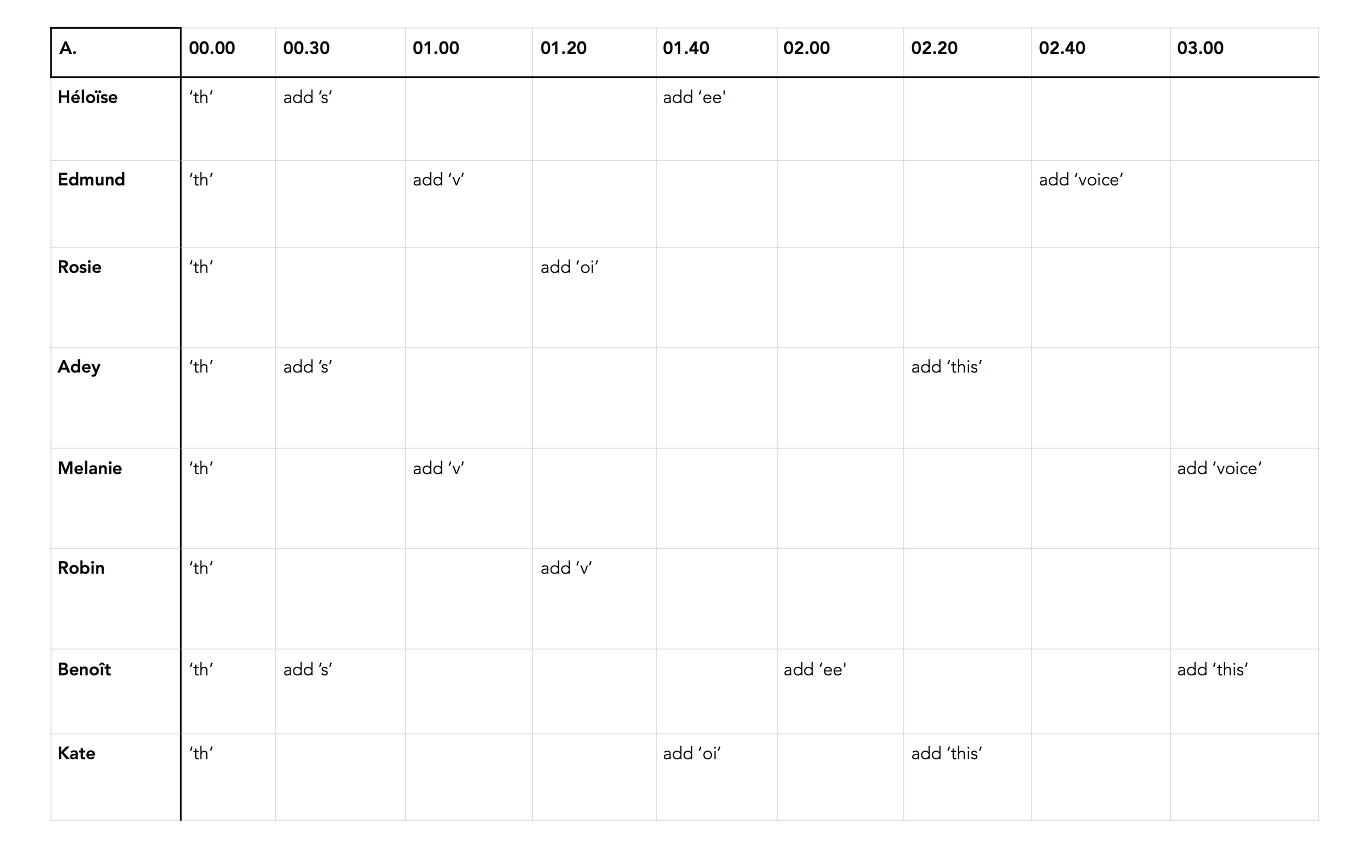
Excerpt from a text score operating metaphorically as a recurrent neural network.
Moving forward
Whilst I have questions, working with PRiSM SampleRNN has inaugurated a new way of thinking about what I’m up to when making music and sound, which for the purposes of this project has meant a strict adherence to the specifics of creating voice to reflect on humanity.
With its iterative process of learning and listening, machine learning models an emphasis on listening deeply to the detail of what exists as a departure point. I find this quite a radical position from an inter-species justice point of view.
I hear in its responses a sort of staging of the tension that exists now between co-existent species, and an emphasis on the movement and shapes of animal voice. This brokers a new type of aesthetic challenge to the narratives I can shape and a real foil to the civilising creep of too much tonal smoothing I might have adopted without this collaboration.
In 2020, I read The Labour of the Inhuman (Part 1 and Part 2) by philosopher Reza Negaristani, which argues that machine intelligence could be seen as a method for reflecting what it means to be human. Specifically, Negaristani describes the project of being human as a path across a constantly shifting landscape, along which the task is to create ‘points of liaison… between what we think of ourselves and what is becoming of us’. He speaks of the need to create new norms for constructing human-ness, and I’ve taken this idea into the core of the way I think about what this project means and what its for.
Pausing for thought at the end of this first stage of development I can see the shape of that path, as viewed through the lens of a music project, through my collaboration with PRiSM SampleRNN. Its patterns, imperfections and brimming intent have created new points of light for triangulating human and non-human to me.
I move forward this year through this new landscape with a revised understanding of my project as being an ongoing act of construction, of it being a ritual space of speculative imagination founded in the absolute realness of solidarity with feather, hand and paw.

